
Understanding ChatGPT Context and How to Work Around Token Limits
ChatGPT Context
One of the innovations of OpenAI's ChatGPT model is how natural it is for users to interact with it. The model seems to maintain a context of a conversation. For example, it will expand on its previous answer when you message "tell me more."
However, if you have communicated with the model long enough or sent a large message, you have probably experienced the model not responding or sending you the following error message:
The message you submitted was too long, please reload the conversation and submit something shorter.
This happens because, in reality, GPT models do not maintain a context of a conversation. When interacting with ChatGPT on OpenAI's website, every new message sent to the model also contains data about the previous messages. For example, if you message the model, "Hi, I'm Dimi. What's your name?" and it answers, "Hello Dimi! I'm ChatGPT. How can I assist you today?", the second message you send will be extended with your first question and with ChatGPT answer before sending to the model.
So, that creates an illusion that ChatGPT maintains a context, whereas the whole conversation is being saved on a website for attaching it to your message before sending it to ChatGPT. As you continue the conversation, each message you send will be extended with the previous messages and outputs before you hit the token limit.
Token limitations
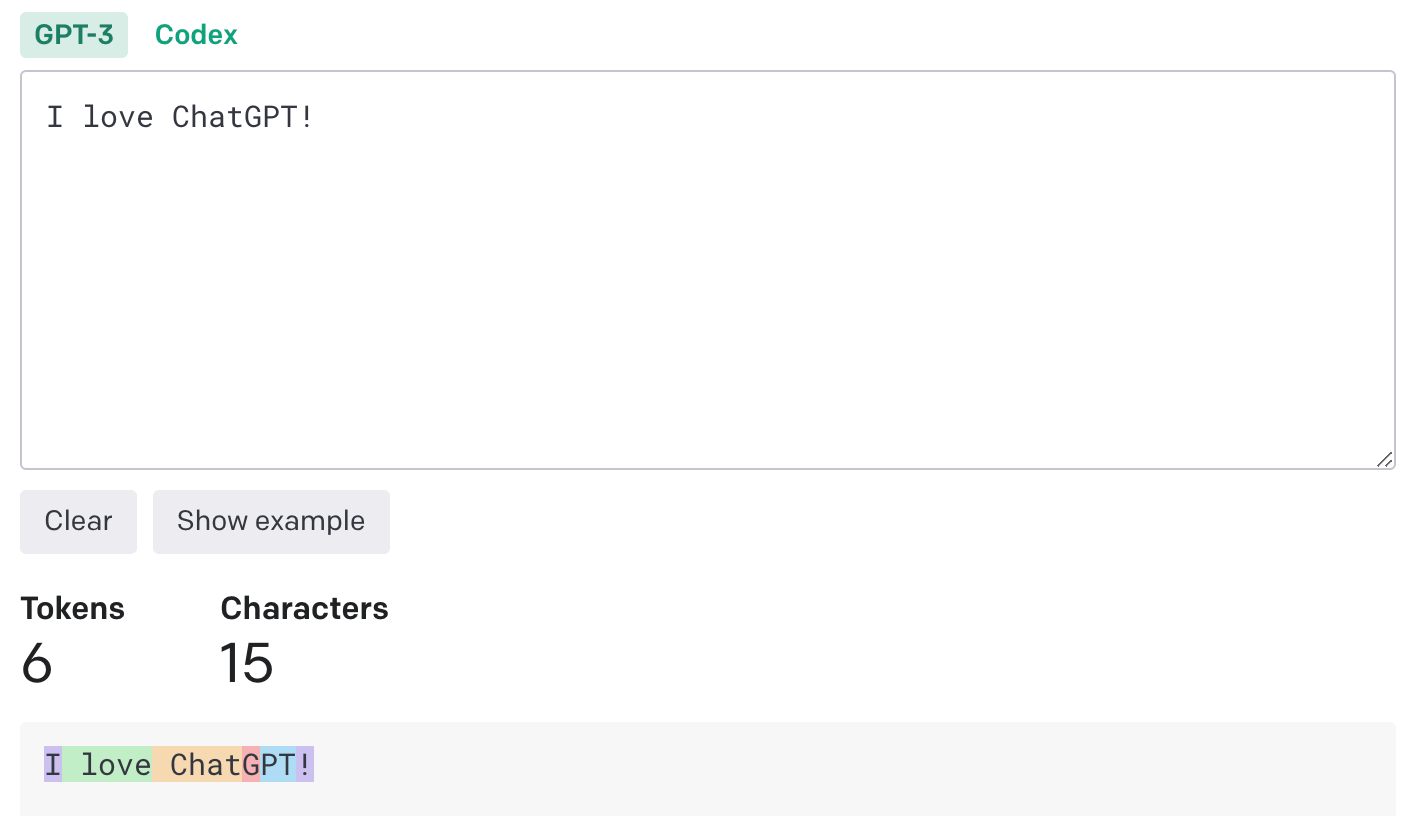
Tokens can be thought of as pieces of words, and they are the building blocks of large language models (LLMs) like ChatGPT. For example, the phrase "I love ChatGPT!" consists of 6 tokens: "I", "love", "Chat", "G", "PT", "!".
You can read how OpenAI counts tokens here.
And you can use OpenAI's Tokenizer to count tokens in text.
The larger the text, the longer it takes for the model to analyze. Therefore, OpenAI limits the token number for a single interaction with the model to ensure efficient performance.
Each language model has a different number of token limits. For example, ChatGPT 3.5 has a 4096 token limit (equivalent to roughly 3,125 words), whereas GPT 4 has up to 32,000 (roughly 25,000 words).
Since we have to attach previous messages to every new message for a model to have a conversation history, we can see how fast the token usage limit grows with each new message. For example, if the first message sent to the ChatGPT contains 20 tokens, the second one might contain 300, and the third might contain 1000 because each new message contains an entire conversation between a user and the model.
Exceeding the token limit will make the model unresponsive or lead to incomplete responses.
Next, we'll look into solutions that can lengthen or altogether bypass the limit.
Using System messages
The system message helps set the behavior of the model. For example, with the following system message, the model will reply with only one sentence as an editor:
Act as a headline editor. You will create headlines for stories. The headline should be one sentence and optimized for SEO.
A system message like this can be helpful when you want the model to reply with concise answers, and it will reduce the size of tokens, but eventually, it will still hit the limit.
Summarizing and Truncating conversation
Another solution is to count tokens of a past conversation with the OpenAI's tiktoken library, and as the tokens approach limit, summarize the past conversation to reduce the tokens count. Eventually, it will require truncating some past messages, but It's a good solution for Chatbots that don't need to maintain a vast context.
Text embeddings and Vector Databases
Although this solution is more complicated, by implementing it, you can potentially have unlimited context for a conversation.
The way it works is that each message is converted into a numeric representation of data (vector embeddings) and stored in a vector database. Then, when a user asks a question, it is converted into embeddings, and the system searches for similar text in the database. Vector databases like Pinecone or Chroma are specially designed for handling this type of data. Finally, the database returns the relevant text shorter than the token limit, and the model answers the question based on this specific text.
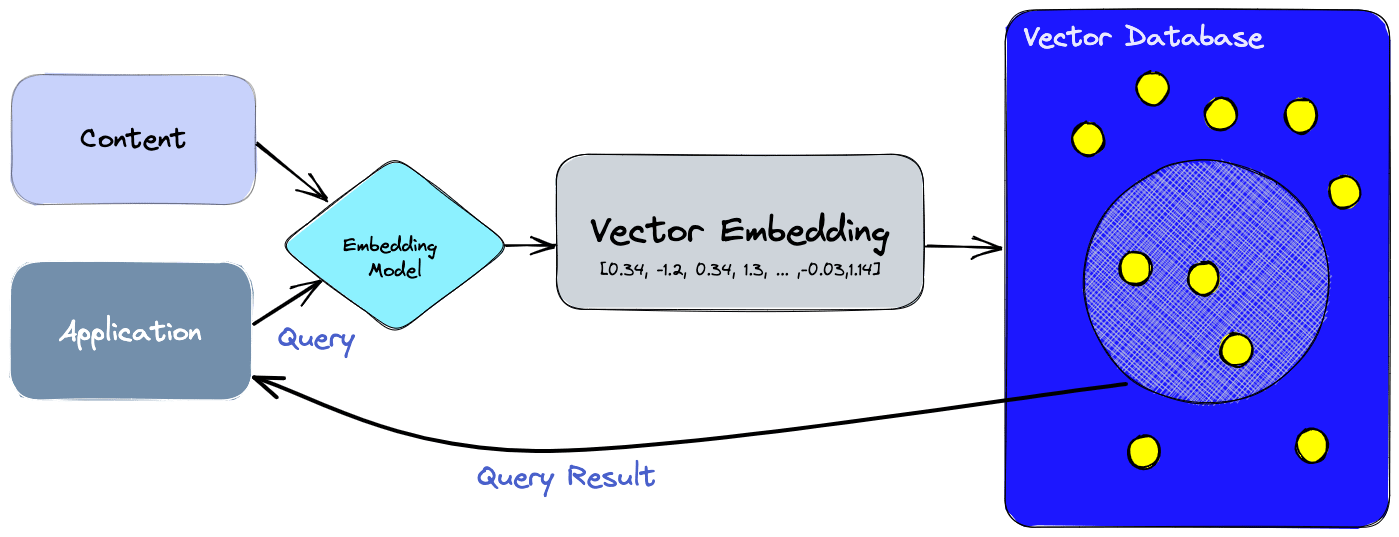
With this technique, you can build Chatbots with unlimited context and software where users can interact with their uploaded documents.
Conclusion
Understanding how token limits work in Large Language Models is crucial for effectively using their capabilities in various applications. In this post, we've discussed simple yet effective solutions to get more results within the token limit and more complicated solutions that bypass the limit. With these techniques, you can build various applications like Chatbots that provide helpful information based on your company's private knowledge base or real-time data, applications that analyze and summarize big data, and other advanced use cases.